MoePC
菜单
切换皮肤
2021Q2 CPU Database
Full SKU Stack Charts
AMD
超微
Ryzen
锐龙
HEDT
高端桌面
Desktop
桌面
Mobile
移动
Ryzen PRO
锐龙PRO
Workstation
工作站
Desktop
桌面
Mobile
移动
Embedded
嵌入式
EPYC
霄龙
Server
服务器
Embedded
嵌入式
Intel
英特尔
Core
酷睿
HEDT
高端桌面
Desktop
桌面
Mobile
移动
Xeon
至强
NVIDIA
英伟达
Apple
苹果
Apple Silicon
Qualcomm
高通
Snapdragon
骁龙
Smartphone
智能手机
Laptop
笔记本
Samsung
三星
Exynos
Exynos
MediaTek
联发科
Dimensity 5G
天玑
Helio
曦力
HiSilicon
华为海思
Kirin
麒麟
Kunpeng
鲲鹏
AMD
AMD
Ryzen
Ryzen
Ryzen 5000
Zen 3/2
Chagall
HEDT
Vermeer
DT
Cezanne
MB
Lucienne
MB
Ryzen 4000
Zen 2
Renoir
MB
Ryzen 3000
Zen 2/+
Castle Peak
HEDT
Matisse
DT
Picasso
MB
Ryzen 2000
Zen/+
Colfax
HEDT
Pinnacle Ridge
DT
Raven Ridge
MB
Ryzen 1000
Zen
Whitehaven
HEDT
Summit Ridge
DT
EPYC
EPYC
EPYC 7003 (Milan)
Zen 3
EPYC 7002 (Rome)
Zen 2
EPYC 7001 (Naples)
Zen
Genoa
Zen 4
Radeon GPU
Radeon GPU
RX 6000
Navi2x
RX 5000
Navi1x
RX 400/500
Polaris
Navi3x
AMD uarch
Zen
Zen 3
2020
Zen 2
2019
Zen+
2018
Zen
2017
Zen 4
2022
Zen 5
TBD
RDNA
RDNA2
2020
RDNA1
2019
RDNA3
2022
GCN
Intel
Intel
Core
Core
11th Gen
Rocket Lake
Tiger Lake
10th Gen
Comet Lake
Ice Lake
Xeon
Xeon
2nd Gen Xeon-SP (CLX)
1st Gen Xeon-SP (SKX)
3rd Gen Xeon-SP (CPX/ICX)
Ice Lake-SP (ICX)
Sapphire Rapids (SPR)
Granite Rapids (GNR)
Xe GPU
Intel GPU
Iris Xe MAX
Xe LP
Xe HPC
Xe HP
Xe HPG
Intel uarch
x86 big
Core
Golden Cove
Willow Cove
Sunny Cove
Cypress Cove
Skylake
x86 LITTLE
Atom
Gracemont
Tremont
Goldmont Plus
Intel Gen
Gen12/Xe
Gen11
Larrabee
NVIDIA
GeForce
Ampere
RTX 30xx
Turing
RTX 20xx
GTX 16xx
Pascal
GTX 10xx
Tesla
Ampere
Volta
搜索
切换皮肤
2022-10-29
Intel 22Q3 财报新信息
2021-08-23
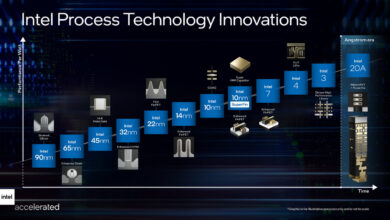
Intel 2021-2025展望 Part0:制程及封装
2021-07-10
代号”Chagall”,AMD Threadripper 5000系列预计于8月份发布
2021-06-30
Intel下代至强Sapphire Rapids 确认延期至2022Q2,性能定位相关
News
Intel
2022-10-29
3
Intel 22Q3 财报新信息
Intel
2021-08-23
2
Intel 2021-2025展望 Part0:制程及封装
AMD
2021-07-10
2
代号”Chagall”,AMD Threadripper 5000系列预计于8月份发布
Intel
2021-06-30
6
Intel下代至强Sapphire Rapids 确认延期至2022Q2,性能定位相关
SKU list
2021-06-27
0
Apple Silicon SKU list
数码科技
2021-06-23
3
SiFive发布P550/P270 RISC-V架构核,Intel 7nm制程平台2022年登场
SKU list
2021-06-19
0
MediaTek legacy (MTxxxx) Mobile SoC SKU list
SKU list
2021-06-19
0
MediaTek Helio Mobile SoC SKU list
SKU list
2021-06-19
0
MediaTek Dimensity 5G Mobile SoC SKU list
Ryzen
2021-05-27
2
AMD Zen 5 CPU 代号 “Granite Ridge (GNR)”
AMD
2021-04-27
4
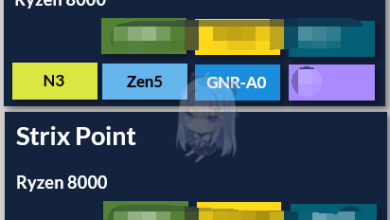
AMD Zen 5 代号”Strix Point” 将采用big.LITTLE架构,使用3nm制程
数码科技
2020-12-28
0
Samsung Exynos Mobile Smartphone SoC SKU list
Intel
2020-12-16
3
Intel 10nm/7nm、ICX、ADL/SPR相关信息【翻译】
SKU list
2020-12-16
0
HiSilicon Kirin Mobile SoC SKU list
数码科技
2020-12-16
0
Qualcomm Snapdragon Mobile Smartphone SoC SKU list
SKU list
2020-12-16
0
Qualcomm Snapdragon Windows PC SoC SKU list
Intel
2020-12-09
0
Intel Core Mobile SKU list
Core
2020-12-09
0
Intel Core HEDT SKU list
Core
2020-12-07
1
Intel Core DT SKU list
Ryzen
2020-12-02
1
AMD Ryzen Threadripper PRO SKU list
1
2
3
»
10
20
...
最后一个
返回顶部按钮