本帖地址:http://www.moepc.net/?post=2442
AMD EPYC 7000系列处理器
对于EPYC的解析已经翻译过了,这里不再长篇大论
地址:http://www.moepc.net/?post=2262
简单来说EPYC就是4颗Zeppelin芯片MCM封装而成,使用InfinityFabric互连
这是AMD将良率(成本)、性能、拓展性综合考虑采取的策略,在后面我们可以看到直接成效。

阵容

Intel Skylake-SP
关于Skylake-X解析也基本都讲过了,这里只放新的PPT信息
地址:http://www.moepc.net/?post=2068
Skylake-SP所用的CPU核相较Skylake-S做了许多改动
Intel首先在Skylake核心外增加了768KB L2,相应的L3从每核心~2.5MB减少到1.375MB,从inclusive变为non-inclusive。同时L1数据缓存带宽翻倍。
管线方面,Port 0/1可以合并为1个512b执行单元来支持AVX-512(低端Skylake-X的AVX-512只有这个)
而Port 5在Skylake核心外加了第二个FMA,只支持AVX-512。

很显然为了marketingIntel会强调AMD Zen核心只有俩128b FMAC,而Skylake-SP有俩256b FMAC以及1个只能用于AVX-512的512b FMAC。
纸面上看AMD的劣势很大,256b AVX2.0指令的数据量是AMD的两倍,如果用上AVX-512,Intel将可执行32次双精度浮点运算,AMD的4倍。
另一方面现实是,刚出不久还比较复杂的AVX-512 ISA需要很长时间才能被大部分软件所采用。最好的结果会在昂贵的HPC软件上,开发商(比如Ansys)会让Intel工程师干苦活:HPC软件要通过费时费力的人工优化才能很好地支持AVX-512。同时其它严重依赖Intel优化良好的MKL的软件也会有明显提升,比如Linpack。

Intel称性能提升了60%。
对于普通用户,编译器目前还无法生成比目前更快的AVX-512代码,即便如此,提升也很有限。就算是最好的情况下,性能提升也会因AVX-512单元的低频率打折扣。

比如Xeon 8176全核可以达到2.8GHz,AVX 2.0下为2.4GHz(-14%),
执行AVX-512时频率大幅降至1.9GHz(-33%)。
所以即便是优化良好的代码,AVX-512也不会给你两倍性能。
非AVX/AVX2.0/AVX-512加速模式频率对比


非AVX加速频率表

AVX2.0加速频率表

AVX-512加速频率表

同时Intel还采用了新的Mesh网格结构,用于解决环形总线拓展效率不佳的问题
详细说明在上面链接

用了9年的环形总线
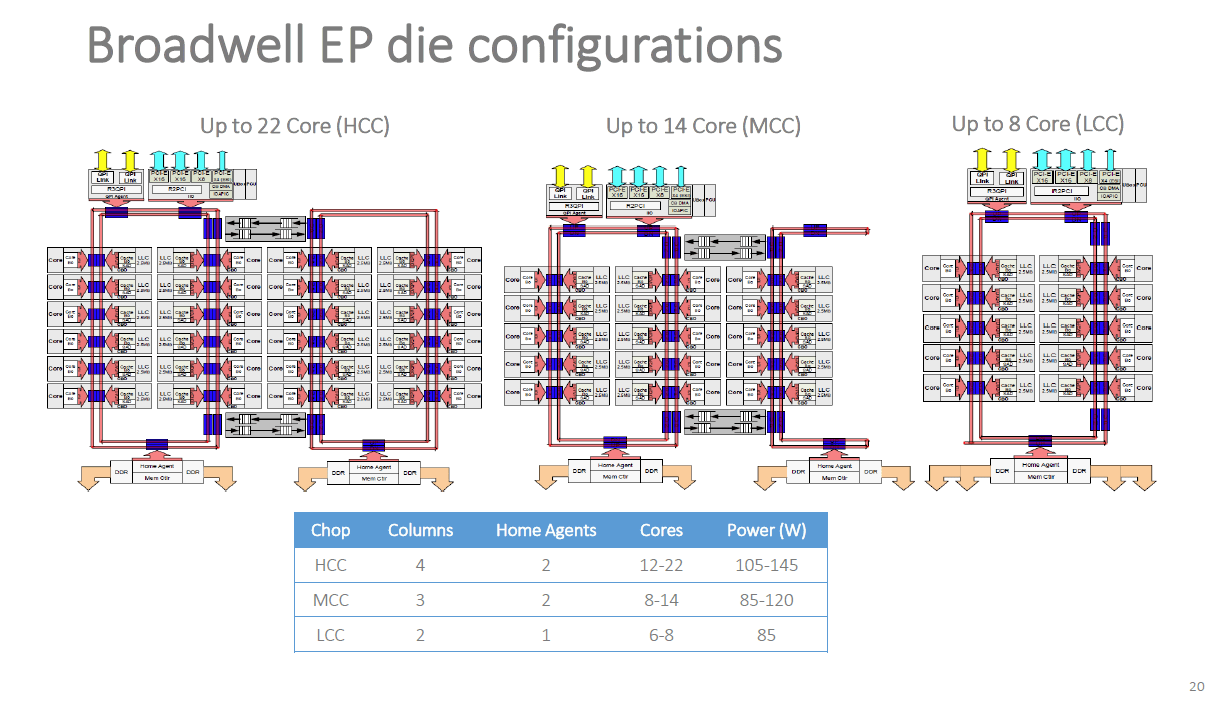
Broadwell-EP
环形总线运行在最高3GHz的频率,而Skylake-SP的Mesh以及L3运行在1.8-2.4GHz之间,意味着更高延迟
同时SKL-SP多出的核心会进一步增加延迟。
Intel声称L3延迟只增加了10%,同时耗电更少。
双环形总线的Broadwell-EP上平均延迟为6个周期左右,略好于Skylake-SP
Skylake-SP同一列两端的两颗核需要4个周期,而同一行两端需要9个周期;最差的情况,对角线需要大概13个周期。
这个数字还是比EPYC的MCM封装间通信要快很多。

Skylake-SP XCC 28C

Skylake-SP HCC 18C
Skylake-SP LCC 10C

Skylake-SP阵容
M:每插槽支持1.5TB内存,为标准版两倍
T:高T-Case,更长寿命
F:集成OmniPath Fabric


Platinum 白金圣斗士
每核心2个AVX-512 FMA


Gold 黄金圣斗士
每核心2个AVX-512 FMA


Silver、Bronze 白银、青铜圣斗士
每核心1个AVX-512 FMA


EPYC/SKL-SP/BDW-EP三者比较

Intel的多核结构更先进,但28核XCC太大,制造成本很高。
AMD的MCM制造成本更低,良率更高。同时内存带宽和容量也高不少。但除开CCX内部,没有统一的LLC来提供核心L2间的低延迟通信。
价格对比

高端同价位AMD比Intel多出10核心(7551/6152),Intel的加速频率更高。
希望Intel价格能更低,AMD中端吸引力再大一点,
而AMD提供的单路EPYC可能是对Intel威胁最大的:双路Xeon 5118和单路EPYC 7551P对比,频率差不多,但AMD多8核,主板更简化,PCIe多许多,TDP也更低,纸面上AMD有许多优势。

测试平台
AMD送来的是旗舰EPYC 7601
Intel让我们在旗舰8180和8176之间选择,考虑到Xeon 8176 TDP和EPYC 7601接近,我们选了Xeon 8176。
测试系统为Ubuntu Server “Xenial” 16.04.2 LTS (Linux kernel 4.4.0 64 bit)
GCC 5.4.0.编译器
SKL-SP “Purley”双路平台

AMD EPYC 7601双路

双路E5 V4/V3

双路SNB-EP

内存子系统:内存带宽
EPYC 7601使用 8通道 DDR4 2400,理论带宽307GB/s
Intel Xeon 使用 6通道 DDR4 2666,理论带宽256GB/s
stream 5.10代码
ICC linux version 17 / GCC 5.4 64-bit
ICC:
icc -fast -qopenmp -parallel (-AVX) -DSTREAM_ARRAY_SIZE=800000000
GCC:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=800000000

AMD说ICC结果不够准确,他们自己优化过后能达到250GB/s。
Intel称AVX-512优化后能达到199GB/s(E5-2699V4: 128GB/s DDR4 2400),这种带宽只适用于特殊优化的AVX HPC应用。
我们的数据更接近实际情况,EPYC的8通道DDR4带宽优势有25-45%。

Skylake-SP的单核带宽比较差:DDR4 2666下只有12GB。Broadwell-EP搭配更慢的DDR4 2400,带宽还要高50%。
而EPYC上单核带宽可以达到27.5GB/s;但单CCX的带宽也只有30GB左右。
SKL-SP的带宽增长比EPYC更加线性。
内存子系统:延迟

AMD方面,同个CCX内L3延迟很低,但CCX间延迟较高。
对于虚拟机(JVM)以及分块并行处理数据的大数据/HPC应用来说没什么影响,但对于需要集中对单一大块数据进行访问的应用,比如数据库来说会有影响。
内存子系统:TinyMemBench
Intel的L3容量逐年增加,V1 20MB,V3 45MB,V4 55MB;延迟也在增长,E5 V4的L3延迟为V1的两倍。所以SKL-SP选择了增大L2,512K时L2的延迟比L3低4倍。
AMD在8MB以内延迟很低,但高于8MB延迟就会大幅增加,高于BDW-EP的内存访问延迟。

单线程整数性能:SPEC CPU 2006
64 bit gcc version 5.4 -Ofast -fno-strict-aliasing -std=gnu89
加速频率对比:
Xeon E5-2690 (“Sandy Bridge”) 加速至 3.8 GHz
Xeon E5-2690 v3 (“Haswell”) 加速至 3.5GHz
Xeon E5-2699 v4 (“Broadwell”)加速至 3.6 GHz
Xeon 8176 (“Skylake-SP”) 加速至 3.8 GHz
EPYC 7601 (“Naples”) 加速至 3.2 GHz
单线程频率AMD有着不小劣势。

5年前的SNB-EP基本都换代了,所以将其作为单线程基准:

首先看不同架构的IPC。AMD EPYC在频率低12-16%的情况下达到Intel架构的90+%性能,显示出Zen架构不俗的IPC。
同步多线程整数性能

SMT效率

AMD的SMT提升为28%左右,比Intel的20%要高。
SPEC 2006 多核
471.omnetpp在EPYC上只能用64线程。解决问题后性能应该会高10-20%。

多线程整数性能


数据库性能:MYSQL Percona Server 5.7.0
使用小数据库,能被L3所缓存:对AMD EPYC来说是最差的场景。
在实际情况中Intel的优势不会这么明显。
如果打开交叉存取性能应该能增加10-15%?


JAVA性能

-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:+UseLargePagesIndividualAllocation


大数据测试 Apache Spark 2.1


浮点性能
C-ray: 针对L1测试
POV-Ray: 针对L2测试
NAMD:针对内存子系统测试




功耗

EPYC 7601在运行整数应用时功耗更高,而用到浮点时Intel系统的功耗就爆炸了(即便不是集中AVX应用)。
结论
首先是价格。如果想要性价比,AMD EPYC更具竞争力。除开数据库和向量化HPC应用,4200刀的EPYC 7601和定价8700+刀的Xeon 8176性能不分伯仲。
价格相近的Xeon 8160核心少了8个,性能要低15%左右,却比EPYC还要贵500刀。
当然一切都取决于最终整个系统的价格,不过看起来AMD在价格上会给Intel很大压力。

Skylake-SP可以拓展到8路系统,说实话这部分市场正在快速萎缩,关系不大。
同时AMD的单路EPYC,甚至更具吸引力。单路EPYC 7551P性能会高于很多双路至强的方案。同价位单路EPYC比双路至强核心多出8个,频率相近,还不需要处理器间的互连 – 主板更简化,更便宜。
然而如果你花大价钱买软件,情况就不同了。Intel的高价不再那么重要,拥有最高单线程性能,高吞吐量,用HPC软件的话还能从AVX 2.0/512中受益。
对于这种人,想完全发挥EPYC的性能就需要更多优化和调整,对于小企业不大可能。但对于有资本进行优化的云服务提供商,这是一次性投资。微软已经开始在Azure 云数据中心中部署AMD EPYC。
展望未来
Intel有更好的结构,以后可以塞进更多核心。
然而AMD也有Zen这一强大武器,向量浮点指令在Zen上更快,且同频整数性能与Intel顶级相当。
双CCX 4xMCM设计留了许多提升空间,期待AMD的下代7nm”Rome”服务器芯片。
AMD这次执行的非常好,在关键市场以低价位带来了有竞争力的性能。
Intel方面 Skylake-SP性能很棒,拓展性良好。但架构的提升被大幅涨价和过度的市场细分所掩盖。

本帖地址:http://www.moepc.net/?post=2442
via:http://www.anandtech.com/show/11544/intel-skylake-ep-vs-amd-epyc-7000-cpu-battle-of-the-decade
原作者:Johan De Gelas & Ian Cutress
MOEPC.NET编译,有删减,转载请保留出处。



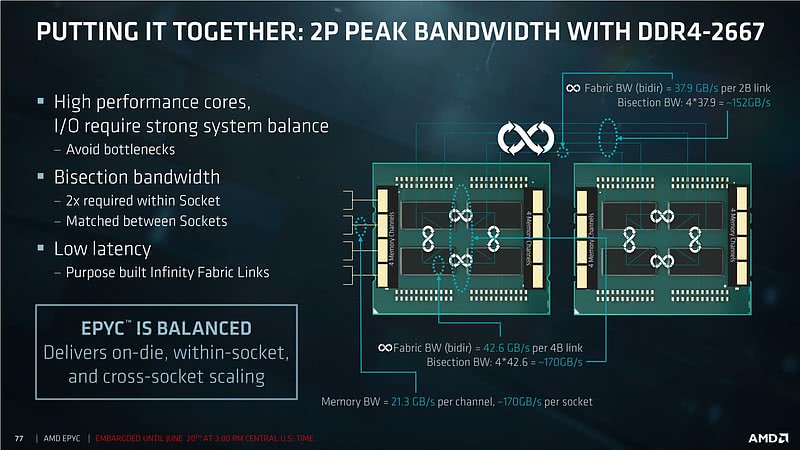
内存带宽那边好像说错了吧_(:3」 ∠)_
应该是153GB/s和128GB/s吧,咋翻倍了喵~
只有我一个人不知道为什么8156这个4核U可以卖7K刀的吗…
@Concord_e:额额 为什么会被识别成奔腾… 明明是1700X呀orz
@Concord_e:因为这不是识别的
@Concord_e:当年E7V4也有类似的东东~
马文,LCC设计完整核心是10核的?
@ayi:嗯,是10C不是12C
所以7900X是完整LCC
@剧毒术士马文:内存控制器好大个啊。
@轮子妈:3通道IMC和一个核心差不多大
@剧毒术士马文
1. 文中fmac是不是应该是fma?
2. Intel将可执行32条双精度浮点指令:如何计算的?
@OoO:32 DP FLOPs/cycle: 每周期2条 8-wide FMA
有两个AVX-512单元,所以应该是每周期32次双精度浮点运算
翻译有点问题
@剧毒术士马文:1, 多谢对第二问题的解答。
2, 第一个问题:
看了原文,就是fmac。AMD’s Zen core has only two 128-bit FMACs, while Intel’s Skylake-SP has two 256-bit FMACs and one 512-bit FMAC.
(http://www.anandtech.com/show/11544/intel-skylake-ep-vs-amd-epyc-7000-cpu-battle-of-the-decade/4)
但是另一篇文章里,作者使用了是fma。Nominally the FMAs on ports 0 and 1 are 256-bit,
(http://www.anandtech.com/show/11550/the-intel-skylakex-review-core-i9-7900x-i7-7820x-and-i7-7800x-tested/3)
我现在就是怀疑原作者笔误。
桌面版 16核心Threadripper1950X定价999美元 12核1920X定价799美元 如何?
祝愿农企在服务器市场也能180度翻身。
我现在就在等amd桌面旗舰上市了。~
以后E5神教要变成EPYC神教了
@hangoverfriday:是4094神教←_←
等待月底的AMD到来,咳咳
amd天下第一!
不知道7601频率爬不起来的bug在不在,至少看功耗还是做不到满频率吃慢tdp
@在amd看大门:估计功耗墙限制住了~
这一年的CPU市场找个词来形容的话,也就只有Ragnarok了