本文地址:http://www.moepc.net/?post=5151
不开玩笑,这次的Architecture Day 大概是Intel 近几年来最有趣,信息量最大的活动了。PR成分较少。在活动上Intel 给出了下代Sunny Cove CPU架构和 Gen.11集显架构的技术细节,并进行现场演示;同时更新了CPU架构和GPU架构的路线图,指明了发展方向;发表了下代封装技术Foveros以及对应产品的信息。
闲话不多说,这大概会是篇很长的文章,大概一次更不完
大家也都知道现在这种活动汇总的文章都是我自己写的东西,已经脱离了以前做翻译的模式。当然更不是某些媒体看着新闻稿写出的猪饲料。
NDA材料和信息这堆东西我早就从Intel 收到了(和国内媒体不同)尊重其他外媒和NDA就没有提前发布,以后也会这样。不过没有到现场,会缺失部分细节,从Anandtech等其他媒体转载引用的部分有注明。
文章顺序和往常的汇总文章一样。
先暂时放出CPU架构及路线图部分。这部分是13号凌晨写的。后续的Foveros 封装、工艺及显示架构部分其实已经写完了,会在后面放出。原因有些人应该懂得。
点击相应标题跳转文章内容
CPU部分:是时候说再见了,Skylake
- Sunny Cove 架构信息
- Sunny Cove架构展示:Ice Lake-U
- Ice Lake-SP 服务器现场演示
- Intel的big.LITTLE: 代号Lakefield
- Core、Atom、Xeon 架构路线图更新
Sunny Cove:是时候说再见了,Skylake
Sunny Cove 架构信息
上一次Intel 发布全新CPU架构要追溯到2015Q3 的Skylake Launch。随着10nm 鸽了又鸽,新架构的发布也只能不断推迟,Tick-Tock变成了P-A-O-O-O-OOMG。

Kaby和Coffee除了频率和核心数的增加外,核心架构算是没动过。得益于14nm原本的制程优势+Skylake的IPC优势,性能在2018年依然有足够的竞争力,功耗方面的问题已经开始显露。

其间出过Cannonlake-U的独苗i3-8121U,对比现有的14nm产品,无论是性能还是功耗都很尴尬,更体现出之前10nm有着严重的问题。【COAG到现在都没法用,Gen10的GPU大概就是因为这个原因大面积挂掉。】
之前旧新闻里有过的信息不再重复:
Intel (临时) CEO Robert Swan 在瑞信 22届TMT大会的演说【摘要】
现在10nm 的日程总算定了下来,Intel 也终于揭晓了10nm的CPU架构:Sunny Cove。
Sunny Cove是Intel的新核心架构名称,源于Intel内部的项目代号。原本公开的名字一直都是Ice Lake,GCC等也是-march=icelake,Intel 从这代开始把核心架构名称和核心代号区分开来。以前Skylake就是Skylake-S/H/U/Y等核心的架构名,现在核心架构名叫Sunny Cove,实际产品的核心代号依然是Ice Lake,比如Ice Lake-U/Y、Ice Lake-SP等。

拿Intel移动版处理器为例
实际产品的核心代号依然为Ice Lake
现在核心架构叫Sunny Cove
另外Sunny Cove 也有不同版本。Ice Lake有Server和Client两版,在Intel的材料中现统一称为Sunny Cove。具体区别未知,根据现在Skylake Client和Server的区别来看,大概是AVX-512单元和缓存配置。

Intel 介绍Sunny Cove的时候,先从核心架构的策略开始。Intel 把性能分为两部分:通用计算性能和特殊计算性能。

通用计算性能的提升主要靠IPC和主频的提升。这个IPC就是大家所泛指的“IPC”,通过更深、更宽的管线【后端】和更先进的算法【前端】来提升每周期指令数。主频的提升就更简单了,通过新工艺节点以及半节点的优化提升频率。IPC和频率基本能在所有的程序里看到效果,简单有效,无需对现有代码进行改动。
Sunny Cove就是依靠上面这些达成更高的性能的:与Skylake相比,管线更深、更宽、前端更加智能。

这次Intel 并没有给出前端的具体数据,说要等到2019年后面才会透露。。。活动上只公开了后端的提升。
Sunny Cove 的ROB、L/S缓冲区、保留站等都在容量上有显著增加。
缓存的话,最明显的大概是L1D,从32KB增加50%至48KB,这是自Nehalem以来,Intel首次增加L1D的容量。
L2缓存也有增加,容量视产品不同有变化。Client 版本应该是512KB,Server 版本会更大【Skylake分别是256KB/1MB】。
μop缓存和二级TLB更大了,具体数据Intel 没有透露,对性能会有较大的正面影响。

Sunny Cove的并行度相比Skylake也有明显增加。
Allocation由4-wide增加至5-wide,总的执行端口从8个增加至10个;
L1的Store带宽翻倍,AGU从原来的2L+1S变成2L+2S;
整数及浮点端口的能力也有提升。
整数方面:Port 0 和Port 6 都获得了LEA单元;Port 1 增加了Mul 和iDIV 单元,原本Port 5 的Mul 单元变为MulHi单元【具体作用未知】。
浮点方面:乍一看只有Port 1 有变化,增加了Shuffle单元

仔细一看会发现有蹊跷。Intel的架构对比图里,Skylake的Port 5 有FMA单元。
而Skylake Client 的Port 5 是没有FMA单元的。
除非Intel打错了,不然这里的Skylake应该是Skylake Server,有俩AVX-512单元:Port 0+1 和Port 5。
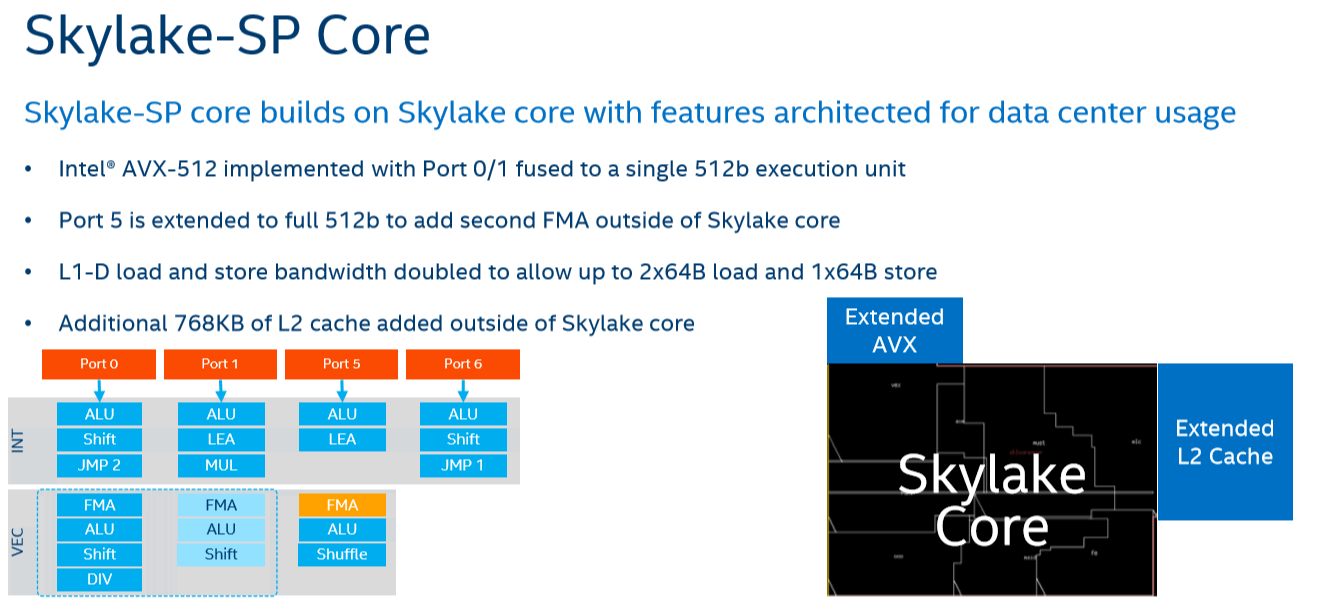

这里的情况有两种可能:
- 1.这个是最可能的情况。Intel 拿Skylake Server 和 Sunny Cove (Server)作对比,两边都有俩AVX-512单元,配置没什么变化。消费级所用的的Sunny Cove(Client)大概不会有Port 5的那个FMA,只有Port 0+1能够执行AVX-512。
- 2. Intel拿 Skylake Server 和 Sunny Cove (Client)作对比。Sunny Cove是支持AVX-512的,所以至少要有一个FMA资瓷AVX-512。第一种可能Sunny Cove (Client)新增加了一个Port 5 AVX-512单元,达到Server的AVX-512性能级别,这个不大可能。第二种可能Sunny Cove (Client)的Port 0+1无法捆绑执行AVX-512指令,只有Port 5能执行,限制到Server 一半的AVX-512性能,这个也不大可能,会浪费太多资源。第三种可能Port 5增加的FMA只支持256b,这样用Port 0+1支持AVX-512,性能不会威胁Server版本,同时执行AVX2等256bit指令时性能还能增加50%。
这一点到目前为止我没看到有任何外媒提到过。具体什么情况只能等Intel透露更多信息,问了也不会告诉我的。。。
以上这些改进能带来多少IPC提升还无法预测,不过个人认为会大于Intel 之前每代的5% 提升就是了….
说完通用计算性能,接下来是特殊计算性能,它是针对特定应用场景和算法进行架构及指令的优化,当然性能提升也仅限于这些应用了。例如AI/ML、加密、压缩/解压、SIMD/Vector 计算等,这些东西主要为企业级市场准备的。
大部分新增的指令集都是基于AVX-512的,会用到AVX-512单元。

Sunny Cove 在加密性能上有明显提升,新增了IFMA(Big-Number Arithmetic)、VAES、Vector Carryless Multiply、Galois Field和SHA-NI 指令的支持。

压缩/解压缩和特殊SIMD/Vector计算方面则新增了VBMI/VBMI2和BITALG指令集。

内存寻址支持也有提升。线性寻址空间为57bits,物理寻址空间为最大52bits。这个最大值应该是为Ice Lake-SP准备的。

Sunny Cove架构展示:Ice Lake-U
Intel在现场首次公开展示了采用Sunny Cove架构的产品,核心代号Ice Lake-U。
Ice Lake-U 预计为4C/8T,GT2 48/64EU【3/4 S】 集显的设计。

现场的Ice Lake-U RVP测试平台
图源:pcwatch


散热器和主板上都有着ICL-U的字样
图源:pcwatch
Intel 称Ice Lake-U 在7zip中要快75%,注意这个并不是之前所说的“通用计算性能”,而是得益于新增的加密指令的“特殊计算性能”,在有加密的情况下,7zip性能高出许多。
拿的是啥对比还不清楚。后面集显展示拿的是Skylake。
采用10nm+工艺(原定),Sunny Cove + Gen.11 架构的Ice Lake家族预计于2019年晚些时候至2020年尽数登场。
Ice Lake-SP 服务器现场演示?
Intel 在Architecture Day 现场也拿出来了Ice Lake-SP的实物。


Ice Lake-SP实物展示
图源:STH
Ice Lake-SP也将采用Sunny Cove 架构,预计缓存和AVX-512单元相比桌面的版本会更多。
现场只给看了块有顶盖的ICL-SP,看不到下面是什么样子。
据Techreport主编Jeff Kampman 称Intel在现场有用Ice Lake-SP做AVX-512的演示,至少说明10nm 生出来了能进行正常工作和演示的孩子。Ice Lake-SP如果继续传闻的单Die设计,面积不会小。
Ice Lake-SP预计将于2020年初到来。
Intel的big.LITTLE: 代号Lakefield,5个核心
这个就非常有意思了。Lakefield的传闻已经有很长时间,现在终于看到它在现实中工作的样子了。

Lakefield 采用Intel 的下代3D封装“Foveros”【介绍已经写完,会在下次更新】,集成度非常之高
封装尺寸只有12x12x1mm。实际的die会更小。

有两颗Die,一颗P1274 – 10nm的Compute Die封装在上面,里面是所有的计算核心(CPU+GPU)。
下面是P1222 – 22FFL工艺的Base die 在下,概念类似于interposer, 但里面集成了SRAM、I/O、芯片组、供电等低功耗电路。
22FFL 别看是“22”,实际上是基于目前Intel 14nm打造的。成本低,漏电也少,Intel 靠它在Lakefield上达成了2mW的Standby power!
Intel 说是某个大客户点名要的产品,所以做了Lakefield 出来。具体是谁我觉得很明显了。
然后Foveros封装之上,再用POP封装进LPDDR4内存,这个现在手机SoC就已经有广泛使用。



现场展示的lakefield。
图源:pcwatch
发热问题如何还不清楚。Intel 已经能拿来正常演示,说明问题不大。Intel说下面的22FFL的发热本身就很低。

至于架构方面,Intel 给的NDA PPT里把这张去掉了。。。上面的图片是Anandtech CPU编辑Ian 拍的图片。
转换一下大概是这个样子:

计算性能方面,CPU为1+4架构,大核是Sunny,官方给的信息只有这么多。
不过不难猜到
1x 大核为Sunny Cove 架构 + 512KB L2,这个推测和ICL-U用的是一个。
官方称之为“High Performance” 高性能核心,为Core #4.
4x 小核为Tremont 架构 + 1.5MB 共享L2,就是下代的阿童木,虽然图上显示的是独立的4个核心,在这里应该是4核组成的一个CMP模块。1.5MB L2相比GLM+的4MB有大幅减少。
官方称之为“High Effciency” 高能效核心,为Core #0-3.
相应的,Intel 在Uncore/LLC部分 增加了4MB L3,这个应该是5个核心共享的。一方面弥补Tremont 减少的L2,L3还能存储数据供big.LITTLE核心之间共享。
奇数个核心+混合架构 这样的配置比较奇葩。
集显则是下代Gen.11 LP集显,和桌面一样的GT2配置,64EU,性能非常可观。目前的阿童木最高只有18EU。
Lakefield 是款非常有意思的产品。在小小的封装里集成了高性能架构,5个核心,64EU的集显,更不用说还有一大堆I/O等电路。
和10nm的FPGA一道,Lakefield 将成为首批采用Foveros封装的产品,2019年发布。
说实话,Foveros 来的这么快着实让我感到惊讶。
Foveros 封装可以说代表了以后移动SoC乃至桌面、服务器领域的未来。即便那未来相对比较遥远。
Core、Atom、Xeon 架构路线图更新


Intel 在活动上更新了CPU核心架构的路线图。
高性能的Core架构方面,现在我们看到的是2019年的Sunny Cove,提升单线程性能、增加ISA、拓展性提升。
2020年会有缓存架构重新设计、晶体管优化、安全强化的Willow Cove
2021年则是单线程性能、AI性能、网络/5G性能均有提升的Golden Cove。
低功耗的阿童木更新就慢一些,2019年是Tremont,单线程性能提升,网络服务器性能提升,10nm更加省电;
下个核心则要到2021年才会更新,Gracemont 带来更高的频率和单线程性能,Vector 性能提升。【或将引入AVX?】
Gracemont 的下代定档2023年前,代号未定,目标是更高的单线程性能与频率,更多新功能。
服务器方面,Cascade Lake 的下代Cooper Lake 将引入BFLOAT16。
Ice Lake-SP搭载Sunny Cove
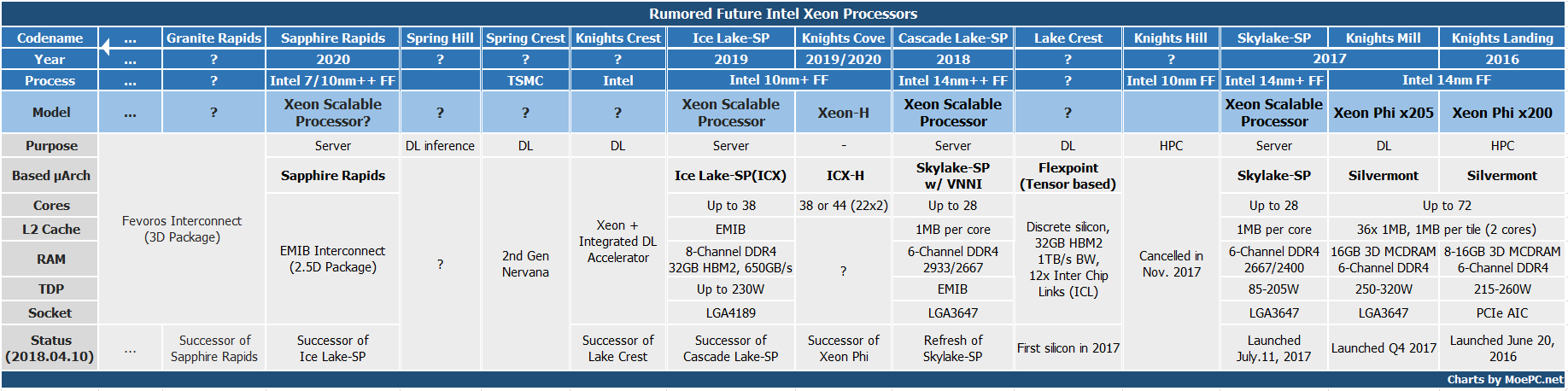
这张半年前我做的路线图,当时知之甚少,有很多错误的地方。
下代不出意外将会是Sapphire Rapids。据说进度有所提前。

另外大家可以猜猜。。。Intel的 28C Xeon 3175X何时解禁
本文地址:http://www.moepc.net/?post=5151
MOEPC.NET编辑,转载请保留出处。
图片来源:
Slides&NDA Information: Intel
Lakefield blockdiagram:Anandtech www.anandtech.com/show/13699/intel-architecture-day-2018-core-future-hybrid-x86
Ice Lake-SP:Servethehome www.servethehome.com/first-pictures-of-intel-ice-lake-xeon-server-chips/
Ice Lake-U/Foveros/Lakefield: PCWatch pc.watch.impress.co.jp/docs/news/1158136.html



留个言坐等更新,intel ice lake的核显性能提升百分比,似乎是64eu的新核显和老的24 eu的hd630的对比?这么看感觉核显的ipc提升不大么。此外,i5-1035G1还是老的核显架构吗
文酱这文章不更了么
intel的cpu架构终于“大”改了
炮湖的AVX512就是Port0+1吧?冰湖是不是该提升一下?
Lakefield是拿出来怼8cx?
Windows那个调度确定可以玩big.little吗(疑惑脸)
AMD那个Dynamic local mode效果都还没有直接关核心来的好
@xing0999:windows其实一直都有big.little,单核睿频是限定某个核心的
当然,你单核程序 跑在big还是little上是随机的。。。需要硬件级别优化
想请教一下,印象里几个月之前一直有人说Intel要用钌代替铜的,现在变成了钴,请问钴和钌哪一个性质更好一点啊?用钴是因为比钌好吗?还是因为目前没法用钌?
@Q:Intel 10nm计划的一直都是钴互联。
http://www.moepc.net/?post=4403
这篇wikichip的文章里写的很清楚
Intel的 IEDM 2017也有介绍。
intel用了cmp搞大小核,有趣。感觉客户还是苹果
@5256qpqp1:也可能是下代Surface Go
@5256qpqp1:Atom一直都是CMP
个人感觉,Zen 2 PK Sunny Cove,IPS方面后者胜出的机率比较大;但如果涉及到具体产品上,多核狂魔AMD猛堆核心,降低售价,Ryzen有望全胜。总结一下,Intel胜在微架构,AMD胜在产品。作为消费者,我们买的是产品,不是产品的某一方面技术。
最后这张半年前的线路图可以更新下嘛
@Quber:目前正在做的有个新的
覆盖所有架构 不光Xeon
明年真是不错的一年
提升ipc的zen2(起码大于等于目前的skylake)
也提升ipc的icelake(大于skylake)
各种好戏上演
比20系这玩意强多了
@wangbaisen1990:不知道icelake和zen2谁的ipc更强
@wangbaisen1990:算算就知道,应该还是sunny cove IPC要高些,而且ISA support也更全
@sandy:那就不知道了
到时候测评出来就知道了
@wangbaisen1990:如果sunny cove的IPC提升小于5%,那zen2有一战之力。
但是考虑到这回先端后端的规模变化,5%肯定是不止的
@sandy:不知道这些前段后段改进效果如何,如果只是强力针对加密性能这些,可能对ipc影响不大
@wangbaisen1990:加大buffer提高hit rate,加宽流水线提高ILP,这两个基本是最简单粗暴的提高IPC的方法了
@wangbaisen1990:这两个提升IPC只是理论上的
Intel 没有公布任何前端改进的细节,不好分析。
冰湖S还要等1年啊
马文姐姐对AMD的新Vega商标有什么解读吗= =
最近刚需需要装电脑,如果新Vega Frontier或者啥的快来了,我就先去找个矿卡顶两天
要是coming sooooooooooooooooooooooooon的话我就买14nm的VFE了……….
@桜道月:买张矿64公版刷FE BIOS吧
@5256qpqp1:V64我有LQ版了
如果我现在买完的话,我的选项有三个
Radeon Pro Duo(fiji)
RX Vega 银风
Vega Frontier
说实话那个VFE蓝色妖姬的外观真的好看)
@桜道月:好像还有金色的?
@5256qpqp1:有的,金色的我都怀疑全球有没有500块…
各种群/论坛,我就没见过有人有过
@桜道月:俺寻思着 虽然下个月CES 但是感觉7nm消费级不会到那么快
现在应该也不会出12nm重制版的Vega
但AMD又去注册了新商标 感觉要么是Ryzen 3000G系列的APU用的,要么就是7nm的Vega frontier
点击标题跳转文章内容那里失灵了,望修正
@theLastWish:OK了
@theLastWish:没。。。没失灵,可能是我浏览器抽了
接下来的什么时候更呐
@fuusen:让我观察观察再
大家最感兴趣的不是已经发了么
@剧毒术士马文:我对foveros更感兴趣,哈哈
大客户是水果?
@LV3的萝莉控:我看到第一反应也是水果
@gavinzyf:放在两年前还有可能,不过今年来看apple明显想把Intel从自家供应商挤出去,A12X已经超越了mba13上的那个破玩意了,高端还有amd这个备胎。Lakefield也许是为Windows重回平板市场做的准备,而且再不加强wintel联盟,amd确实要开始挖墙脚了
@gavinzyf:什么,那个大客户不是水果吗?
作为一个外行感觉英特尔产品线好复杂,hedt已经被9900k这样的高端消费级干掉了,所以下一步怎么走呢?
@今石老贼:先把9900k价格降下来再说
@theLastWish:降价还得靠农企
@今石老贼:你也看linus。感觉这频道有点中年危机,虽然没直接说推荐,不过自从他把surface go拿上桌面他已经多少沦成半个中关村。
@游客:老莱和炮村还是完全不一样的,毕竟凭一个自媒体的体量和影响力做到厂商纷纷跪舔。他现在的问题是PC市场衰退,热点话题越来越少。
sunny cove后端都是10 issue了前端还只有5 dispatch,这个配置说实话有些让人看不懂。
现在提升IPC也只能靠堆料了…
@sandy:增加管线长度就必须堆缓存,而且现在没完整公布前端,分支预测的改进对性能有较大影响,可以期待一下的。
而你单单说靠堆料,制程提升目的就是更高集成度堆更多的料…
@liubeixi:分支预测提高可以提高前段的有效throughout,但是个人还是觉得5 dispatch相比于后端的10 port来说小了些,可能是PD上有些压力。
堆料=加大buffer,加宽超标量。这种改动相对来说是比较简单的,但是上限也很明显,以后是越来越难以持续的。从现在的信息来看,sunnycove并没有什么显著的微架构突破,主要还是在原有的基础上靠“堆料”来提升ipc。当然也有可能只是现在intel还没有公布更多细节,期待有当年uop cache这样的好点子
@sandy:SKL的Allocation Width已经是6了,至少根据官方优化手册是这样,不太懂为什么这次发布会突然出来了Allocation Width只有4的说法,按照这个Sunny Cove反而变窄了?不太可能。
按照Agner的说法,SKL的throughput只有4uOPs/cycle,但很显然SKL最窄的地方(decode)也是5-wide,我怀疑他是直接拿Haswell复制粘贴的,除非说他把L1 fetch带宽定义为瓶颈。
Allocation的宽度远小于Port数是很正常的,一是有fused uOP二是有些uOP需要大于1个cycle来执行,所以所有的x86架构的瓶颈都是宁可让部分执行单元饿着来换取灵活性和峰值吞吐量,不然就会变成Bulldozer那样从前到后都被噎死。